Business Rule Driven Just-in-Time Network Access

One of the most incredible achievements of the late 20th century is the internet. It has connected the world in ways never imagined and enabled businesses, organizations, and individuals to do incredible things efficiently and at a global scale. One of the groups it has enabled, unfortunately, is criminals. Since the first networks were connected, criminals and malicious users have exploited weaknesses in software and configuration to disrupt business and steal money, technology, and peace of mind. The connectivity of the modern world is the greatest feature and the greatest weakness. Recently, Zero Trust has become the new security model. Zero Trust is an evolution of earlier models, addressing their weaknesses and giving a framework to deliver much more secure systems and networks. NetFoundry, the sponsor of the free and open-source OpenZiti project, is at the forefront of this movement, providing many Zero Trust features, and enabling others. The API-driven and software-embeddable nature of the OpenZiti project gives flexibility for simple solutions that have outsized impacts in reducing some of the most common risks seen in information systems today.
The Problem
The connectedness of networks and applications is their reason for existing, but as mentioned, also a significant problem. The point of Zero Trust is to ensure that whenever an information resource is accessed, the accessing entity is fully authorized to do so, and continuously so. In many cases, this is difficult to do, especially to deploy widely. Time has shown us that many attacks start in "smaller" systems; those that are not considered critical, but give attackers a foothold inside a network to pivot from. There is also a major risk of malicious or accidental access by internal or other authorized users, or those posing as them after successfully infecting a device or stealing credentials. Suppose network layer access, reachability at the socket level, can be tied dynamically to business rules. In that case, we can reduce risk by orders of magnitude, both from malicious actors, and accidental actions by authorized users. I will describe one such solution we have developed here at NetFoundry for our use, the access to supported resources deployed as part of our service. I have adjusted the numbers involved to make the math simpler.
Standard support tickets flow in from customers, whether they are internal or external, to a support team, which then acts upon them. In some cases, depending on the ticket type, support personnel will have to access the systems in question, often with elevated privileges, to triage, troubleshoot, and repair the problem at hand. For a support team of 10 people, supporting 2500 devices, we can present a simplistic risk score in person hours of access and will assume the probability of malicious or accidental action is constant. We will credit the existing system with only allowing work-hours access, though 24 hour remote access is also fairly common. Given those inputs we can see the weekly exposure is 40 (hours) 10 (engineers) 2500 (devices) = 1,000,000 exposure units (person-device-hours). Let's see how we can bring that down.
A couple more numbers: average ticket time is 2.5 hours, with 20 tickets per day, and 4 average devices affected per ticket. This means that if we can reduce the access to rule authorized users and devices, we change the exposure units calculation to 2.5 (hours) 20 (tickets) 4 (devices) * 7 (days) = 1400 exposure units.
While this is a purely hypothetical example, one can understand how it would affect their environment. By driving access only via active tickets, we have reduced the risk exposure by 99.9%+. Mileage will vary widely, but the numbers remain eye-popping regardless. And let's be clear, the risks in this kind of environment of friendly fire are at least equal to those of malicious action. Support organizations tend to have personnel at different levels of capabilities and may be supporting a wide range of devices and types. How many times has someone logged into the wrong device, or opened another production device for comparison and then made changes to that one instead of the one they intended? Any support manager will have a myriad of stories to tell you if you ask. In my own experience, a coworker once logged into a production router during a class by the vendor, and then accidentally ran the next lab exercise on the production device, causing a major outage via an honest mistake and a momentary lapse in judgment.
The Solution
Detailed information regarding the details of this particular solution design is available in the associated GitHub repo. The ticketing system in this case is Zendesk. Zendesk, like many support solutions, has several integration points, one of the most general is a webhook. For those unfamiliar, a webhook is a method to send a message to an http/s endpoint delivering a data payload for processing or logging, similar to a machine-to-machine text message. In our case, we use this method to send a few key pieces of information to a function hosted by AWS Lambda. A few relevant data points are enclosed in the message, the ticket number, an identifier for the devices involved, a Network ID, the assigned engineer's name, and the status, along with a security key. The ticket number is to reference back when we close the ticket and remove the access, as well as to make the actions human-readable to trace back actions through logs.
Process Flow
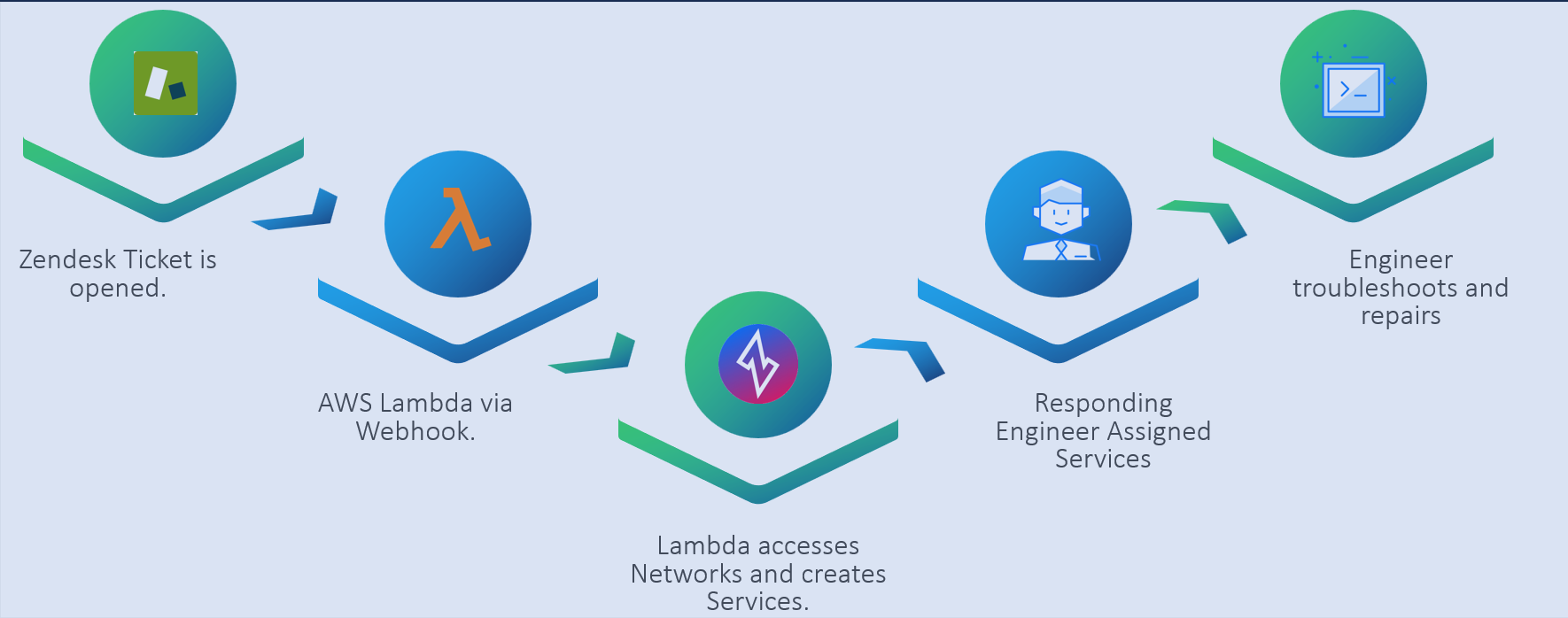
When a new ticket is opened, the Network ID is selected for the ticket when relevant. This list is updated every few hours by a separate Lambda function as the list is highly dynamic, and must be kept current. The engineer that "caught" the ticket is assigned by the system when it is opened. When the ticket moves from a status of "New" to "Open", or a new user is assigned, the webhook is sent to the Lambda.
The Lambda function authenticates the message and then acts on the context of the data provided. In our case, this uses the Network ID to look up all the nodes associated with that network. It then builds a series of services in the Ziti network that allows access to SSH (port 22) on these nodes. In this case, all nodes deployed have a security group rule to allow a specific address through for this purpose; until now, we have used the "Dark Bastion" architecture, and this is an evolution to remove the bastion process itself. The policies are then applied to grant the authorization to the assigned engineer to those nodes. While this seems like a lot of work and would be if it were done manually, the use of the available APIs of the CloudZiti network means that from ticket opening to the services being available to the engineer is usually less than 30 seconds. The engineer then simply needs to open an SSH connection to the service name(s) created by the system.
When the ticket status is changed to "Solved", the process is reversed. The webhook is sent to the lambda with the ticket number and the new status. The function then removes the services, policies, and attributes, removing the connectivity, again within 30 seconds or so.
All the creation and deletion events are logged by the system as change events, and utilization and other data is emitted as well as part of normal network operations. Every step of the process provided auditable logs for review and forensics.
The Benefits
Looking at this process through a MITRE ATT&CK lens, we can see that it disrupts many of the TTPs common to breaches, and some of the more intractable ones in concert with the rest of the environment. A recurring issue in breaches is the use of valid credentials. Whether devices are lost or stolen with information on them, passwords are reused, or are successfully phished, once a malicious actor has those credentials, a great deal of damage can be done. The Continental Pipeline breach was of this sort, to the best of public knowledge. However, even having full control of a system in this state is meaningless if the connectivity itself is ephemeral and tied to additional business rules. While it may not block 100% of risk, it can significantly reduce the blast radius of the worst compromises; full control of a privileged user. When one deploys this sort of network, it is simple to only allow the inbound traffic to ssh or other management and administrative ports to a few devices, in our case, the Edge Router serving the services described here and our orchestration platform. This disallows techniques like lateral movement, as the devices are not allowed to connect to one another's administrative ports, only a few dedicated devices. This mitigates any presence established on these units and makes reviews much easier. The logs provided by Ziti also allow a fine-grained level of information about who connected to what devices at what time and from where. This makes any forensic investigation much easier, as well as allowing general log spot checking, or long-term storage for potential later investigations simple as well. Many other TTPs are potentially interrupted by this architecture, depending on the design of the rest of the environment. Zero Trust is about the whole, not a single product, and security in layers is still how one achieves it.
Conclusion
This process allows us to provide frictionless access to relevant resources for a support team in real-time while blocking access whenever the business rules don't allow it, dramatically reducing the potential risk of accidental or malicious actions. This example is only that, an example, and while focused on a support ticketing process that we use at NetFoundry, it shows the flexibility of using features and functionality of common software packages, the APIs provided by Ziti (available in both CloudZiti and OpenZiti), and a little software "glue" to implement a very powerful process reducing risk and increasing the security posture. A similar solution could include an additional human check, one could easily envision an operations manager receiving a request from an external contractor for access to a system, and authorizing a period via a mobile app. Or having incident response specialists in a central group or a vendor that are granted network access to a business unit, or specific resources for forensic and other response functions only when driven by an incident, and requested by the responsible incident commander. The logging and other features of the systems provide additional reviewability, especially in situations where end devices may not support full authentication and authorization feature sets, such as many industrial control systems, sensor nodes, or ancillary devices. In a world plagued by security breaches, novel thinking about how we use existing features and functionality can be very powerful in protecting the information assets of people, organizations, and enterprises.
An Easy Experiment
A simple entry point to this sort of just-in-time access is the zrok project. Zrok is a solution built with OpenZiti and its original purpose was to provide an easily consumed solution for ephemeral access. In the short time it has been available, it has already started to grow in some amazing directions, with new features and improvements to the user experience. Available for free, users can set up and run public or private endpoint access to any system, from anywhere, in almost no time at all. Very useful in its own right, zrok also evidences the capabilities of OpenZiti in this space very well, as the base network access is achieved using the available functions of the OpenZiti solution.